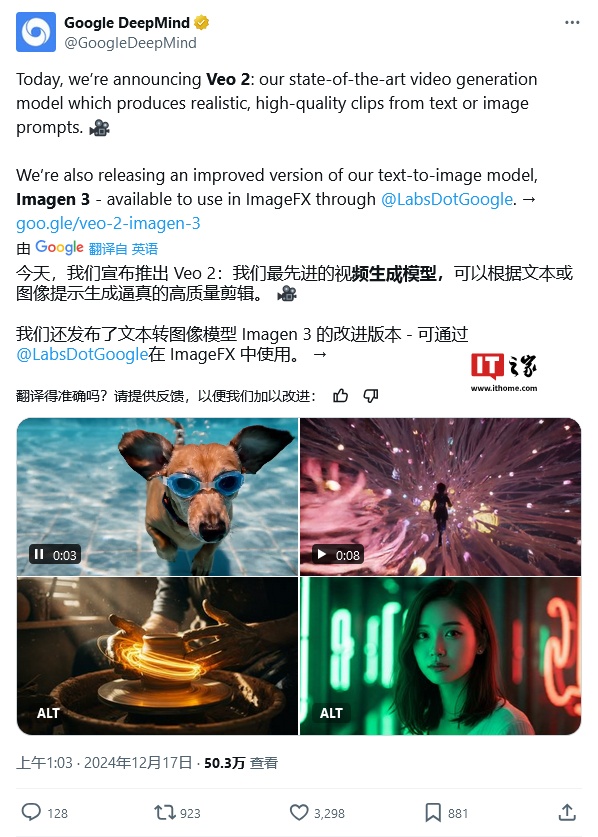
谷歌公司今天(12 月 17 日)发布公告,正式发布了视频生成模型 Veo 2,官方声称新模型可以更好地理解现实世界物理、人类运动及表达的细微差别,进一步提升整体细节和逼真度。
谷歌 Veo 2 模型可以生成分辨率最高 4K(4096 x 2160 像素),时长为 2 分钟的视频片段,相比较 OpenAI 的 Sora 模型,分辨率是后者的 4 倍,时长是后者的 6 倍。
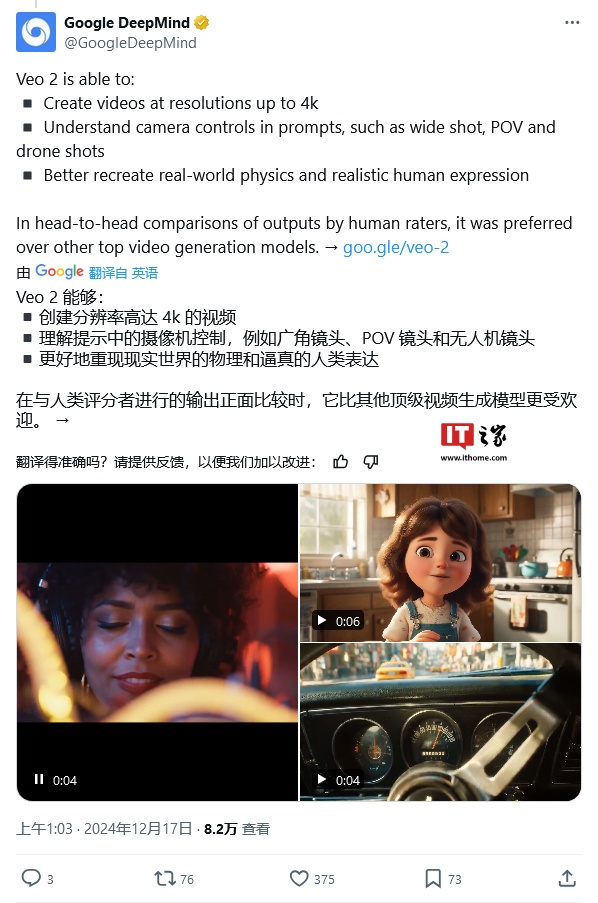
不过目前在 Google 的实验性视频创建工具 VideoFX 中,Veo 2 模型分辨率上限为 720p,长度为 8 秒。
DeepMind 产品副总裁 Eli Collins 表示:“在接下来的几个月里,我们将根据用户的反馈继续进行迭代。”


与 Veo 一样,Veo 2 可以在给定文本提示或文本和参考图像的情况下生成视频,还可以更真实地模拟运动、流体动力学和光的属性。据 DeepMind 称,这包括不同的镜头和电影效果,以及“细致入微”的人类表达。
Deepmind 表示,为了降低 Deepfake 的风险,利用专有的水印技术 SynthID,它将隐形标记嵌入到 Veo 2 生成的帧中。



