
近期,合成数据在大模型中应用的话题引起广泛关注。6月,英伟达发布新一代开源大模型Nemotron-4 340B,其指令模型训练是在98%合成数据基础上完成,此前英伟达还推出了合成数据生成工具Omniverse Replicator,能够生成物理模拟的合成数据,用于自动驾驶汽车和机器人的训练。7月,苹果也发布了其自研的人工智能系统Apple Intelligence,在预训练阶段也大量使用了合成数据。围绕合成数据的价值、应用、风险等,值得我们深入思考,基于此,本文从合成数据的概念入手,分析如何生成合成数据、其主要应用领域、使用合成数据的风险挑战,并探索未来发展前景。

合成数据概念及兴起缘由
合成数据并不是一个全新的概念,早在1993年,著名统计学家Donald Rubin在论文中提出合成数据的概念。近年来,随着ChatGPT的火爆和生成式人工智能技术的发展,合成数据概念受到越来越多的关注。
众所周知,大模型训练和开发对数据尤其是高质量数据的需求量日益增长。然而,现实世界中大模型训练所需数据量却日渐紧张,面临“不够用、不好用、不能用”等诸多问题。
1.不够用
当前大模型训练对数据的需求量远超数据的增长量,知名研究机构Epoch AI在一篇论文中指出,到2026年,大模型将消耗尽所有高质量数据,低质量数据将在2030年~2050消耗殆尽,而所有图像训练数据在2030年~2060年被消耗完。2024年6月,《麻省理工技术评论》刊出一篇论文也指出,高质量数据将在2028年前后被消耗完(见图1)。另外,由于成本问题,也会导致某些数据难以获取。
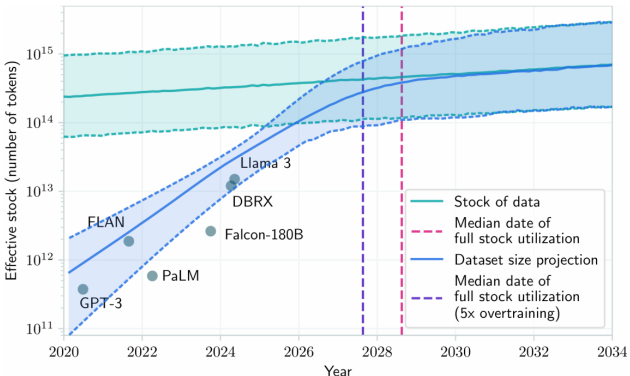
图1 人类高质量数据存量与大模型训练所需数据量的预测1
2.不好用
现实世界中存在数据质量参差不齐的问题,数据中存在错误、缺失、异常、格式不一致等情况,例如打了马赛克的图片,都会使得模型分析结果产生偏差。
3.不能用
随着数据使用监管加强,数据隐私保护法律法规日益完善,对涉及个人隐私权、肖像权、个人真实信息等数据的保护力度加大,要求企业在大模型开发和应用中,不得随意使用上述数据。
这些问题一定程度上制约了人工智能发展,合成数据应运而生。合成数据(Synthetic Data)是指通过计算机算法生成的模拟数据,它模拟真实世界的数据分布和特征,通过数学模型和生成技术,来构建新的数据集,而不是直接来自现实世界的观测或记录。合成数据可以通过针对性的数据补充和强化,解决数据匮乏、数据质量不足等问题;可以规避数据隐私、安全、保密等风险,在医疗、金融等领域意义重大;还可以模拟和生成现实世界中难以采集到的边缘场景,保持数据的多样性。
总之,合成数据为解决上述问题提供更多方向和思路,极大拓展了AI应用的可能性。Gartner、Accenture等著名咨询公司都看好合成数据的发展前景,认为合成数据有望解决人工智能未来发展的“数据瓶颈”,成为推动AI技术更广泛应用的核心要素。

合成数据如何生成
合成数据技术路线众多,常用的有以下三种:基于LLMs生成的合成数据、基于GANs或者Diffusion Models生成的合成数据、基于统计和模拟生成的合成数据,在实际应用中多种方式往往相互协同和补充,以提升数据合成质量。
1.由LLMs生成的合成数据。
LLMs拥有卓越的语言理解和表达能力,以及强大的指令遵循能力,能够为特定场景和领域创建定制的数据集。使用LLMs生成合成数据的常见做法,可分为提示工程和多步骤生成2。首先,基于高性能模型的提示工程生成合成数据,用于补充特定领域的数据,帮助轻量级或下一代模型进行监督学习。如Meta Llama 3的后训练完全依靠从Llama 2获得的合成数据;又如OpenAI计划使用o1模型生成合成数据来训练即将推出的Orion模型。其次,基于模型生成多步骤的合成数据,可用来补充思维链(CoT)的中间推理过程,促进模型的对齐与进化。如浙大、中科院等机构利用GPT-4-Turbo生成代码绘制图像,并逐步提示模型生成解释答案的原理,从而组成多模态合成数据集,使用该数据集对Vanilla Llava-1.5-7B微调能显著提升其视觉推理能力,在推理难度最高的路线图场景中,准确率提升67.4%3。
2.由GANs或者Diffusion Models等算法生成的合成数据。
通过对抗训练和逐步去噪的过程,模型能够生成与真实数据高度相似的合成图像样本,广泛应用于数据增强、医疗隐私等领域。
3.基于传统的统计和模拟等方法生成的合成数据。
一方面通过观察真实的统计分布,利用算法生成符合特定统计分布的数据。另一方面,可以通过模拟器等方法创建数据,如Sora文生视频模型用到Unity、Unreal Engine等游戏引擎合成的视频数据作为训练集。
目前,市面上有许多工具可生成合成数据,如英伟达发布3D仿真数据生成引擎Omniverse Replicator、微软开源合成数据工具Synthetic Data Showcase等。6月14日,英伟达发布开源大模型Nemotron-4 340B,包含基础模型Base、指令模型Instruct和奖励模型Reward,也可用于生成高质量合成数据(流程见图2),其中Instruct模型用于生成基于文本的合成输出,Reward模型对生成的文本进行评估并提供反馈,指导迭代改进并确保合成数据的准确性。
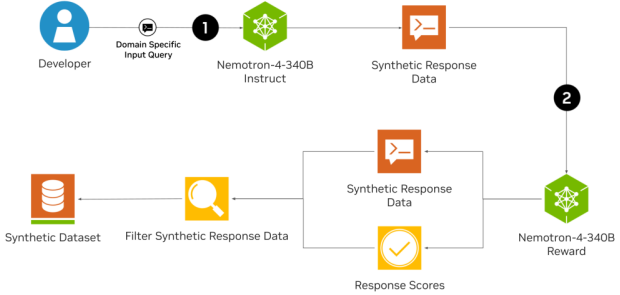
图2 Nemotron-4模型生成合成数据的流程

合成数据的应用实践
近年来合成数据在具身智能、自动驾驶等领域得到重点关注及广泛应用,如成立于2023年初的光轮智能公司,专注于在自动驾驶、具身智能等领域提供合成数据解决方案,在2023年完成种子轮、天使轮、天使+三轮融资,累计融资金额达数千万元人民币,并于2024年5月底完成Pre-A轮融资。
1.合成数据为具身智能带来了丰富、可控且经济的训练与学习材料,提升具身智能系统在各种复杂环境和任务中的适应性和表现能力。
人类远程操控机器人完成任务并生成高质量数据,其收集成本高昂且耗时,合成数据成为“扩大机器人学习的强大且经济”的有效途径,通过数字孪生技术,让机器人在虚拟世界学习如何操作和感知环境。如英伟达与UT提出MimicGen数据生成系统,通过对人类演示进行处理,自动生成不同场景下的大规模合成数据集,用于机器人的模仿学习。在Square、Coffee Preparation等18个任务中,只用175个人类示例就生成超过5万个训练数据集,并且在Square任务中,只用10个人类示例就生成了1000个训练数据集,覆盖不同场景配置,并将成功率从人类示例数据集的11.3%提升至90.7%,在复杂的Coffee Preparation任务中,成功率从12.7%提升到97.3%4。
2.合成数据为自动驾驶领域带来丰富的训练资源,提升自动驾驶系统的性能和安全性。
在自动驾驶车辆的开发过程中,边缘场景(如复杂交通、恶劣天气等)的数据采集尤为困难,国内领先的数据仿真平台公司51Sim利用先进的仿真技术构建各类低概率、高风险的边缘场景,增加训练样本和多样性,提升感知算法泛化能力,帮助主机厂加速模型训练。同时,51Sim参与北京大学牵头的“面向自动驾驶场景的高真实感数据合成”研究课题5,通过将自动驾驶示范园区典型的真实场景与拟真度极高的渲染算法进行集成,生成带有多模态数据标注的高逼真合成场景数据集,大幅推动视觉大模型和高速脉冲视觉模型算法研究评测在自动驾驶场景中的落地应用。

合成数据的挑战及应对
由于合成数据的生成机制和技术特性限制,其应用存在一定隐忧。今年7月,Nature一篇最新论文显示,运用合成数据迭代训练9次,导致大模型不可避免走向崩塌。同样,杜克大学助理教授Emily Wenger发表在Nature上的一篇社论文章也指出,基于合成数据训练的大模型生成的图像会扭曲狗的图片。其本质原因是由于使用合成数据进行模型训练会忽视异常值和偏差值,从而导致原始数据分布的长尾消失,而经常出现的内容被无限放大,模型越来越偏离原始数据分布。
这正是合成数据应用存在的挑战之一,即数据保真度问题,合成数据无法完全模拟真实世界的复杂性和多样性,这会影响模型的训练效果和推理能力。挑战之二,即数据偏差问题,如果合成数据的生成过程本身存在偏差,例如人工恶意植入错误信息或误导信息,合成数据会继承甚至不断放大这种偏差。挑战之三,即可信度问题,合成数据的产生过程通常是“黑盒”的,难以解释生成数据的具体原理和过程,可能导致对合成数据的来源和质量产生质疑。挑战之四,即法律和监管问题,目前合成数据的监管体系尚不完善,如何确保合成数据的合规使用,如何解决带来的新的安全问题,这都是需要进一步考虑和研究的问题。
在技术方面,应对挑战的有效方法之一是采取“混合数据”策略,即在大模型训练中输入多样化的数据,保持真实数据的一定比例。如在大模型预训练阶段仍以真实数据为主导,合成数据作为针对性补充和拓展则保持较低占比(如5-10%);而在对齐阶段,提升合成数据占比,使其与真实数据规模相当,甚至可以更高。其他应对方案还包括调整生成参数、提供多样的提示等。
在监管方面,应注重合成数据的隐私保护和数据安全、合规使用、法律和伦理考量、持续监督与评估等多方面的规范和引导。2024年7月15日,新加坡个人数据保护委员会(PDPC)发布了《合成数据生成指南》,对合成数据的生成技术、典型应用、生成步骤等进行详细说明,提供了合成数据生成技术和方法指导,并强调了隐私保护与数据质量控制的重要性。欧盟颁布的《通用数据保护条例》(GDPR)对合成数据的生成和使用提出了监管要求;今年6月,欧盟数据保护监管机构(EDPS)发布的关于生成式人工智能数据合规指南,为合成数据的合规使用也提供了一定参考。我国于2022年11月发布《互联网信息服务深度合成管理规定》,对深度合成技术使用进行系统性规定,促进深度合成服务规范发展。

合成数据的未来发展展望
合成数据领域正迎来快速发展,其应用前景广阔,据Gartner预测,2024年AI训练中用到的数据有60%是合成数据,到2030年绝大部分训练数据将是合成数据。据著名市场调研机构Nester预测,全球合成数据的市场呈现蓬勃发展趋势,年复合增长率达35%,预计到2035年底,合成数据市场规模将达124.5亿美元(见图3)。可见,合成数据作为数字经济时代的“新型石油”,将为推动人工智能产业乃至经济社会快速发展提供新动能。
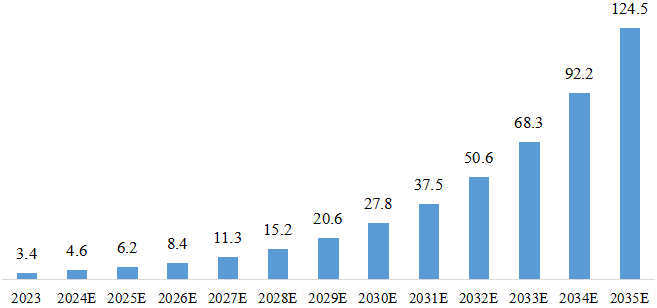
图3 合成数据全球市场规模预测(亿美元)6
总之,合成数据或成为推动大模型能力跃迁的重要突破口,带来广阔市场前景和全新商业机会,但其本身也存在数据质量、技术突破、法律监管等挑战,应从技术、产业、监管等多方面持续研究和探索,共同推动合成数据走向“科技向善”。
注释
1.Will we run out of data? ,《麻省理工技术评论》,2024.6。
2.On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey, 《Computer Science》, 2024.06。
3.Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model, 《Computer Science》, 2024.09。
4.MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations,Conference paper,2023.10。
5.该课题为科技部科技创新2030—— “新一代人工智能”重大项目“人工智能基础模型支撑平台与评测技术”中的课题研究五。
6.数据来源:nester,https://www.researchnester.com/cn/reports/synthetic-data-generation-market/5711
本文作者

虞苏妍
战略发展研究所
高级分析师
高级工程师,拥有20年通信行业研究经验,长期从事产业研究、战略评估等,近年来专注产业数字化、数字政府等领域。

左芳芳
战略发展研究所
二级分析师
硕士,战略发展研究天翼智库数据中心,长期从事行业洞察与研究工作,近期聚焦产业数字化、数字政府、大数据等研究领域。

田盼
战略发展研究所
副主任分析师
高级工程师,就职于中国电信研究院,长期从事产业数字化政策、需求和趋势研究。



