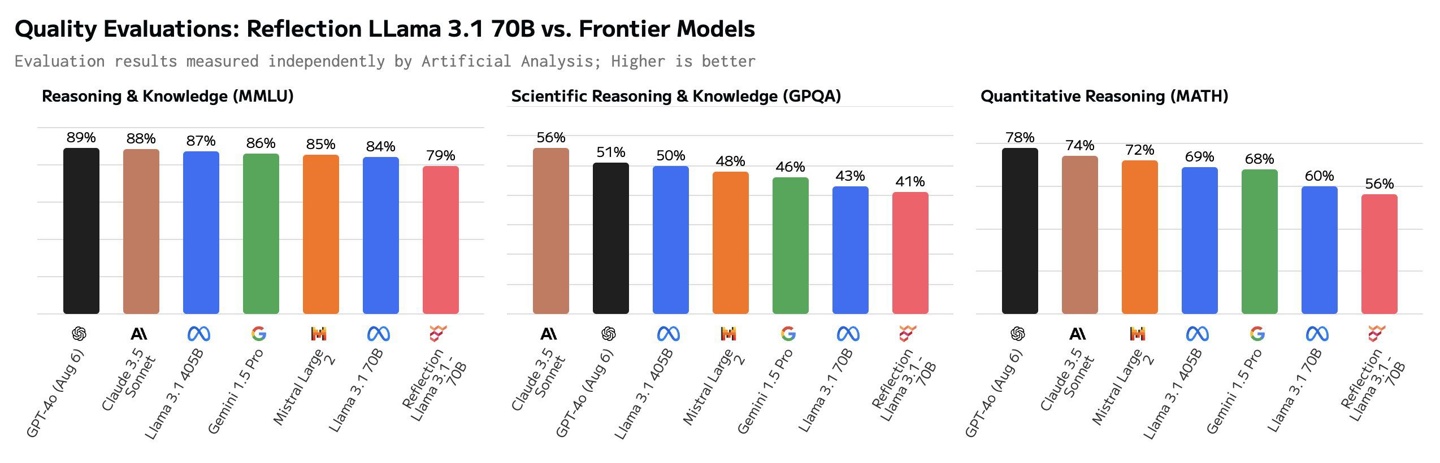
科技媒体 The Decoder 昨日(9 月 10 日)报道,对比平台 Artificial Analysis 相关数据表明,Reflection 70B AI 模型在基准测试中的表现,实际上不及 Meta 的 LLaMA-3.1-70B。
针对 AI 模型基准测试结果不佳,Reflection 公司首席执行官马特 舒默(Matt Shumer)表示,上传模型权重至 Hugging Face 时遇到问题,所使用的权重是多个不同模型的混合体,而他们内部托管的模型则显示出更佳的结果。
舒默随后向部分用户提供了独家访问内部模型的权限,Artificial Analysis 重做了测试,并报告结果优于公开 API,只是他们无法确认所访问的具体是哪个模型。

Reflection 在 Hugging Face 已上传了新的模型,不过这些模型在测试中的表现明显逊于之前通过私有 API 提供的模型。
查询公开资料,有用户还发现了证据,表明 Reflection API 有时会调用 Anthropic Claude 3.5 Sonnet 以及 OpenAI。

舒默旗下公司 OthersideAI 此前已宣布计划于本周发布一款基于 LLaMA 3.1 450B 的更大、更强大的模型。
舒默对这一即将发布的版本做出了大胆声明,称其不仅将成为最佳的开源模型,还将是有史以来最优秀的语言模型。
官方回应: