苹果公司最新发布论文 [PDF],分享了关于 Apple Intelligence 模型的相关细节,部分性能已经超过 OpenAI 的 GPT-4。
模型简介
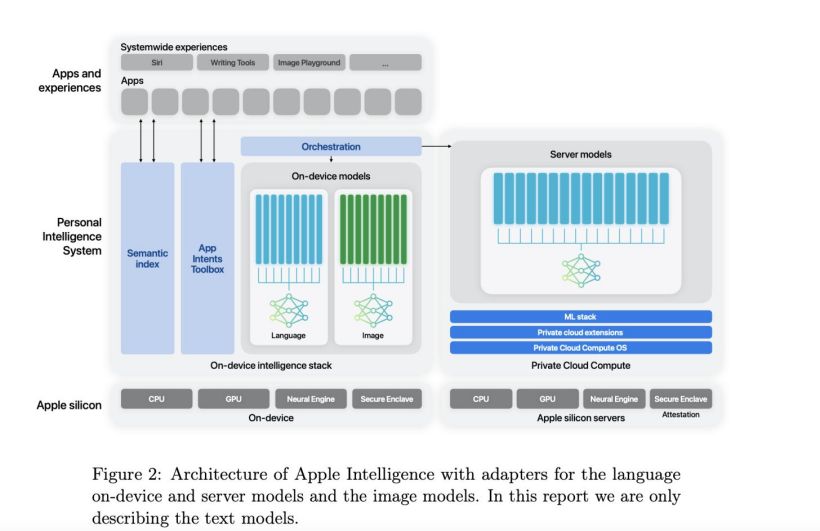
苹果在论文中介绍了 Apple Foundation Model(下文简称 AFM)模型,共有以下两款:
AFM-on-device:本地运行,30 亿参数,可以在 iPhone、iPad等设备上高效运行;
AFM-server:苹果尚未公布参数等细节。
训练数据来源
苹果表示训练数据集包括从出版商处获得授权的数据、经过策划的公开或开源数据集以及我们的网络爬虫 Applebot 抓取的公开信息组成。
苹果强调注重保护用户隐私,数据混合物中不包括苹果用户的私人数据。
据《纽约时报》报道,苹果公司在 2023 年底与 NBC、Condé Nast 和 IAC 等多家出版商达成了价值至少 5000 万美元的多年期协议,在出版商的新闻档案中训练模型。
苹果的 AFM 模型还在 GitHub 上托管的开源代码上进行了训练,特别是 Swift、Python、C、Objective-C、C++、JavaScript、Java 和 Go 代码。
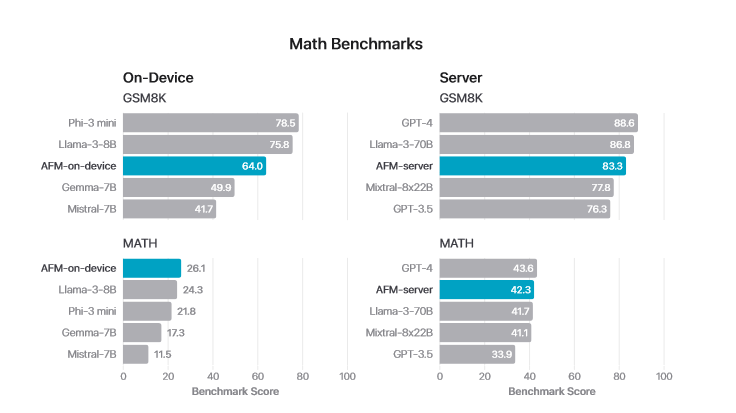
论文称,为了提高 AFM 模型的数学技能,苹果公司特别在训练集中加入了来自网页、数学论坛、博客、教程和研讨会的数学问题和答案。
苹果利用了高质量、可公开获得的数据集(论文中未提及名称),这些数据集“拥有允许用于训练...... 模型的许可证”,并经过过滤以去除敏感信息。
AFM 模型的训练数据集约有 6.3 万亿个 token(token 是小块数据,通常更容易被生成式人工智能模型吸收)。相比之下,这还不到 Meta 用来训练其旗舰文本生成模型 Llama 3.1 405B 的 token 数量(15 万亿)的一半。
训练硬件
根据论文描述,苹果公司使用 8192 片 TPUv4 芯片训练 AFM-server 模型;2048 片 TPUv5p 芯片训练 AFM-on-device 模型。
每个 v5p pod 由 8960 个芯片组成,每秒的浮点运算(FLOPS)和内存分别是 TPU v4 的两倍和三倍,训练模型的速度快了近三倍。

模型性能
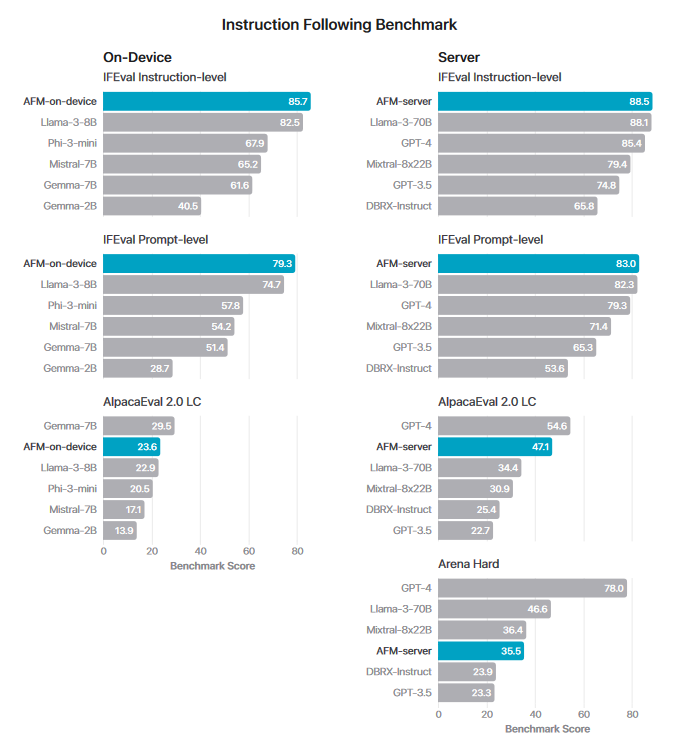
根据论文描述,苹果自研大模型在指令遵循、文本总结方面测试超 GPT-4。
苹果公司的数据显示,AFM-server 有害输出违规率为 6.3%,明显低于 GPT-4 的 28.8%。同样,在设备上,AFM 7.5% 的违规率低于 Llama-3-8B(由 Facebook 母公司 Meta 训练)21.8% 的得分。
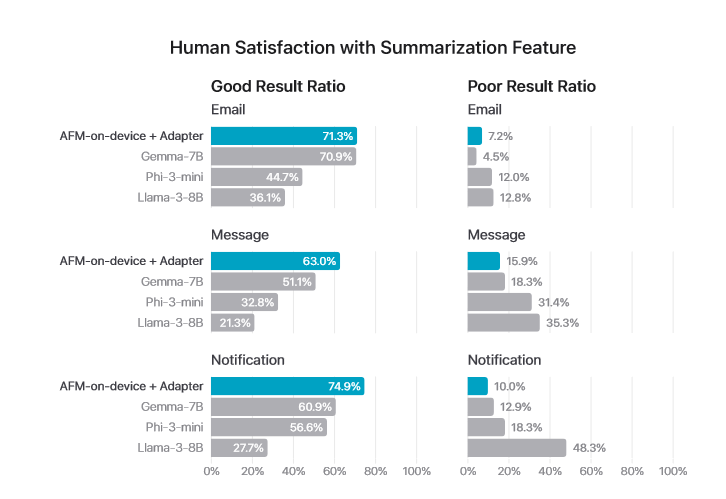
在电子邮件、信息和通知汇总方面,设备上的 AFM 的满意度分别为 71.3%、63% 和 74.9%。研究论文还指出,这三个模型分别领先于 Llama、Gemma 和 Phi-3 模型。IT之家附上相关性能结果如下: