过去一年多来,大语言模型(LLM)从 GPT-3.5、GPT-4 到 Llama等开源模型,一直备受关注。然而,近期一些迹象表明,小语言模型(SLM)正逐渐获得越来越多的重视,微软、GOOGLE等AI领域的大佬们纷纷开始下注小语言模型。出现这一趋势的原因何在,将给运营商带来哪些启示?
大语言模型轻量化渐成趋势
LLM (大语言模型)的参数数量可以达到数千亿甚至数万亿。而SLM(小语言模型) 通常具有数亿或数十亿个参数,SLM 的训练和运行所需的时间和资源要少得多,这使得它们更加适合于资源有限的设备和应用。
1. 多家AI巨头引领,发布多款SLM小模型
微软2023年 9 月发布了 Phi-1.5 版本,13 亿参数。1.5版本可以写诗、写电子邮件和故事,以及总结文本。在12月14日更新发布了 Phi-2 ,拥有 27 亿参数。今年4 月 23 日,微软发布了 Phi-3 Mini,这是Phi-3系列小型模型中的第一个,Phi-3 Mini 可测量参数仅为 38 亿,并在相对于 GPT-4 等大型语言模型更小的数据集上进行训练,现已在 Azure、Hugging Face 上可使用。Phi-3 Mini 的性能比前一版本更好,与 GPT-3.5 等 LLM 不相上下,微软后续还计划发布 Phi-3 Small(7B 参数)和 Phi-3 Medium(14B 参数)两个版本。
今年2月,Google 发布了 Gemma 2B 和 7B,这两款模型更适合简单的聊天机器人和语言相关的工作。Gemma 模型可轻松运行在普通设备上,无需特殊硬件或复杂优化,它提供高效、易用的语言处理体验。Gemma 在 Hugging Face 的下载量已经突破 400,000 次,并激发了Cerule、CodeGemma等创新项目。性能表现方面, Gemma在MMLU、MBPP等18个基准测试中,有11个测试结果超越了Mistral-7B等模型。
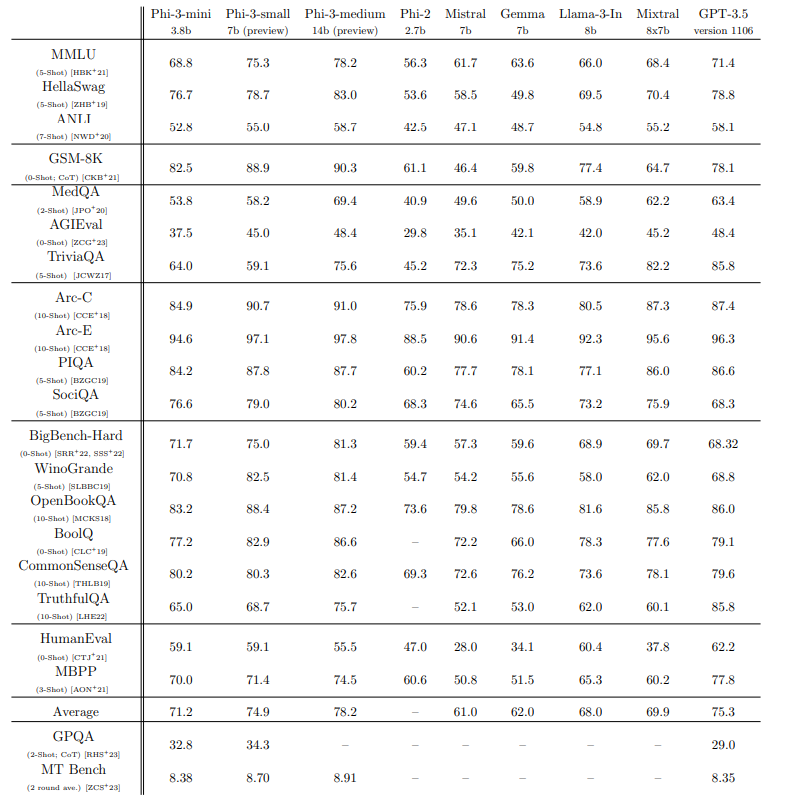
图1:Phi-3与Gemma、GPT3.5等模型的测试对比(数据来源:Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone)
2. 大语言模型轻量化的几个特征
除了原生的SLM小语言模型外,大语言模型也在通过各种手段压缩规模,以期适应更多的应用场景。模型压缩的方式主要包括模型量化、知识蒸馏、模型剪枝、低秩适应、权值共享、结构搜索等。目前,多个大语言模型均已推出“小型化”和“场景化”版本,为端侧运行提供了基础。例如,Google PaLM2中最轻量的“壁虎”壁虎(Gecko)可实现手机端运行,速度足够快,不联网也能正常工作。Meta在官网上公布了旗下最新大语言模型Llama 3。已经开放了80亿(8B)和700亿(70B)两个小参数版本,Llama 3 8B模型在MMLU、GPQA、HumanEval等多项性能基准上均超过了Gemma 7B和Mistral 7B Instruct。

表1:大小语言模型的特征
SLM和LLM的对比
1. 技术特点
SLM通常采用传统的Transformer架构,而LLM则采用更复杂的架构,如GPT-3的解码器-编码器架构和Megatron-Turing NLG的解码器-编码器-解码器架构。
大语言模型遵从缩放定律(Scaling Laws),简单而言就是规模越大,性能越强。相较而言,LLM的特点是性能和泛化能力强,SLM的特点是训练和运行成本低。
2. 优劣势比较

表2:LLM和SLM的优劣势比较
3. 应用场景
在应用场景上,LLM主要运行于云侧,应用于泛场景的通用性和复杂推理任务, SLM主要应用于端侧设备和特定领域的任务。由于端侧设备数量巨大、存在广泛, HuggingFace 的CEO Clem Delangue 甚至指出,多达99% 的使用场景可以通过 SLM 来解决。高通的报告也预测,数量可观的生成式 AI模型可从云端分流到终端上运行。

图2:数量可观的生成式 AI模型可从云端分流到终端上运行。(来源:高通:混合AI是AI的未来)
运营商发展大语言模型面临的问题
1. 资金、技术、数据、人才等方面存在短板
LLM可以充分发挥电信运营商云、网、算力等资源的优势,更好地泛化到新任务和新数据,应用于更广泛的场景。但是, LLM 的训练和运行需要大量算力,训练时间长,部署和维护的难度高,与其它大语言模型一样,存在偏见和安全风险。不仅如此,与互联网巨头比,运营商在资金、技术、数据、人才等方面都存在一定短板。资金上,互联网巨头有更广泛的融资渠道;技术上,与前沿大语言模型相比,运营商大语言模型在参数数量、性能上存在差距,研发处于跟随地位;数据上,优质数据集的数量和质量有限;此外,AI研发人才也短缺。
2. 应用场景受限
LLM大模型的应用场景主要有通用场景,如机器翻译、问答系统、文本生成等,以及结合行业数据集的行业应用。对于运营商的LLM,目前来看,主要应用场景内部可用于客服、网运,外部可泛化为政企客户和公众客户提供通用的AI服务。
通用的AI服务由于市场已有大量的大模型厂商,竞争激烈。垂直行业应用将是运营商LLM未来最大的市场领域。垂直行业通常有较为专业的数据集,数据质量高,数据规模不一定大,但对数据隐私和安全性要求高。从模型的角度来看, LLM大模型虽然通过泛化能适应这些需求,但付出的各种成本高,且存在安全风险,这将制约运营商LLM的广泛应用。
对运营商的启示
1. 面向众多行业应用场景,加强对SLM的研发
随着AI技术的不断发展,SLM 的性能和功能将进一步提升,终端的能力也越来越强,未来越来越多的AI推理工作负载在手机、PC、XR 头显、汽车和其他边缘终端上运行,SLM将会有更大的应用潜力,会有越来越多的场景使用 SLM。
运营商有庞大的客户群,不同客户对与AI的需求千差万别。以政企业务为例,目前政企产品分为标准化产品和平台、小微ICT项目、复杂集成DICT项目三大类,对于标准化产品和平台,运用云和LLM的能力,能够很好地为客户AI赋能,而对于小微ICT项目、复杂集成DICT项目,很多场景下,SLM会是客户更佳的选择。
2. 用SLM降低研发运营成本,促进创新和迭代
SLM 的开发和维护成本相对较低,风险也较低,更容易实现创新和迭代。同时,边缘终端能够以很低的能耗运行SLM,提供更高的能效,借助端侧SLM的能力,能有效降低云侧的资源消耗,帮助运营商降低数据中心的能耗,实现企业的降本增效。
不仅如此,SLM还可以帮助构建运营商的AI生态,加强服务能力,增强客户粘性,提升客户满意度。可以通过SLM开源社区、广泛的SLM客户群,建立良好的AI生态,利用 SLM 进行快速试错,探索新的应用场景和商业模式,成熟后还可以与LLM 结合应用于更复杂的场景,促进运营商各类业务的发展。
3. 通过LLM和SLM结合建立差异化竞争优势
在 LLM 领域,大型科技公司已经占据了领先地位,单纯通过LLM的竞争,运营商较难取得优势,对于一些内部数据集规模比较小的客户来说,使用小模型更具性价比。运营商可以通过LLM和SLM结合,在特定领域形成差异化竞争优势,例如专注于垂直行业,采用低成本、高性能的 SLM 模型,以较低的成本实现服务的智能化升级。而对于客户更加复杂的AI需求,则可通过网络和云端LLM来实现,解决SLM性能和知识的局限问题。
根据客户的业务需求选择合适的模型,通过云侧LLM和端侧SLM相结合,相信运营商能够建立差异化竞争优势,构筑企业更加坚实的护城河。
本文作者

刘敬东
战略发展研究所
二级分析师
硕士,就职于中国电信研究院,长期从事电信新产品、客服服务、数字化转型等领域的研究。



